Blogger で記事を書いていて、やっぱり Markdown でさくさく書きたいなあと思ったので、Qiita を試してみました。
uchan_nos / 最近の投稿
Blogger は HTML と CSS を直に編集でき、柔軟性は高いです。しかし、そんなに柔軟性は要らないからもっとさくさく書きたい私にとっては、ちょっと使いにくいブログシステムでした。コードのハイライトも SyntaxHighlighter などの外部ツールを入れる必要がありますし。
Qiita なら Markdown で書けるし、デフォルトで様々な言語の色分けに対応しているしで、非常に楽ですね。ということで、今後は Qiita に記事を投稿していくことになると思います。よろしくお願いします。
2015年12月13日日曜日
【Ubuntu】ラップトップ PC の蓋を閉じてスリープさせる
LAVIE Direct HZ というラップトップ PC に Ubuntu 15.04 を入れて使ってる。この PC は 13.3 型もの大きさがあるのに非常に軽く、筆者のお気に入りだ。ただ、残念なことに蓋を閉じてもスリープモードにならない問題があった。

蓋を操作するたびに "Unknown key pressed" が記録される。ラップトップの蓋のスイッチが開閉を感知すると、OS に対してあたかもキーボードが打鍵されたかのように信号を送るようになっているらしい。しかしそのキーを OS が知らないために解釈し損ねているというメッセージだ。
Configure unrecognized keys in Linux - Juan Valencia's website には、キーが打たれたときに何が起きるかが詳しく書いてある。簡単に説明すると、キーが打たれるとキーボードから「スキャンコード」が OS に送信され、OS が持つ対応表を元に「キーコード」へ変換される。先のエラーメッセージは、その対応表に登録されていないスキャンコードが送られてきたという意味だ。
この中から XF86Sleep や XF86WakeUp というキーを探す。見つけたらそのキーコードを覚えておく。筆者の環境ではそれぞれ 150, 151 となっていた。
これが分かれば、後は setkeycodes コマンドで設定するだけだ。ただし、xmodmap で表示されたキーコードから 8 を引いた値を設定する必要があるようだ。
うまくいかないときは、試しにアルファベットのキーコードを設定して蓋を開閉してみて、ターミナルに文字が入力されるかを見てみると良いかもしれない。想定した文字が入力されるかを見れば 8 を引くべきかどうかを確認できる。
/etc/systemd/system/set-lid-keys.service
systemd の一般的な説明は他に譲るとして、上記の設定項目を簡単に説明する。
設定ファイルが準備できたら、システム起動時に読み込まれるように systemctl コマンドで有効化する。
これで設定は完了だ。
蓋を閉じてもスリープしない
蓋を開閉して dmesg を確認してみると、次のようなメッセージが出ることが確認できた。
蓋を操作するたびに "Unknown key pressed" が記録される。ラップトップの蓋のスイッチが開閉を感知すると、OS に対してあたかもキーボードが打鍵されたかのように信号を送るようになっているらしい。しかしそのキーを OS が知らないために解釈し損ねているというメッセージだ。
Configure unrecognized keys in Linux - Juan Valencia's website には、キーが打たれたときに何が起きるかが詳しく書いてある。簡単に説明すると、キーが打たれるとキーボードから「スキャンコード」が OS に送信され、OS が持つ対応表を元に「キーコード」へ変換される。先のエラーメッセージは、その対応表に登録されていないスキャンコードが送られてきたという意味だ。
蓋の開閉をスリープボタンに対応させる
エラーメッセージにもあるように、OS にそのスキャンコードがどのキーコードに対応させるべきかを教えるコマンドが setkeycodes である。蓋を閉じたときにスリープさせたければ、スキャンコード e02b をスリープボタンと同じキーコードに対応させれば良い。スリープボタンのキーコードは xmodmap コマンドを使って調べる。$ xmodmap -pke | less
この中から XF86Sleep や XF86WakeUp というキーを探す。見つけたらそのキーコードを覚えておく。筆者の環境ではそれぞれ 150, 151 となっていた。
... Keycode 150 = XF86Sleep NoSymbol XF86Sleep Keycode 151 = XF86WakeUp NoSymbol XF86WakeUp ...
これが分かれば、後は setkeycodes コマンドで設定するだけだ。ただし、xmodmap で表示されたキーコードから 8 を引いた値を設定する必要があるようだ。
$ sudo setkeycodes e02b 142 $ sudo setkeycodes e02c 143
うまくいかないときは、試しにアルファベットのキーコードを設定して蓋を開閉してみて、ターミナルに文字が入力されるかを見てみると良いかもしれない。想定した文字が入力されるかを見れば 8 を引くべきかどうかを確認できる。
起動時に自動的に設定する
このままでは、PC を再起動すると設定が初期化されてしまうので、PC を起動するたびに自動的に設定を行うようにしたい。Ubuntu 15.04 では標準で systemd が起動時の処理を担当しているので、それに合わせて設定ファイルを書けば良い。/etc/systemd/system/set-lid-keys.service
[Unit] Description=Set Keycodes of LID Keys [Service] ExecStart=/bin/sh -c "setkeycodes e02b 142; setkeycodes e02c 143" Type=oneshot [Install] WantedBy=default.target
systemd の一般的な説明は他に譲るとして、上記の設定項目を簡単に説明する。
- ファイル名:普通のジョブを表す .service という拡張子を付ける。
- Description:ジョブの説明文。
- ExecStart:実行させたいプロセスを書く。絶対パスで書かないとダメらしい。
- Type:oneshot は一度実行してすぐ終わるジョブを表す。
- WantedBy:default.target は systemd が起動すると必ず実行されるターゲット。他には graphical.target なども有るが、どれが最適かは筆者は知らない。
設定ファイルが準備できたら、システム起動時に読み込まれるように systemctl コマンドで有効化する。
$ sudo systemctl enable set-lid-keys.service
これで設定は完了だ。
2015年9月27日日曜日
Joel on Software 読書のすすめ
皆さんは "Joel on Software"(日本語訳版『ジョエル・オン・ソフトウェア』オーム社) という書籍をご存知だろうか。この本は Joel Spolsky という人がソフトウェアに関わる様々なこと、例えば言語選択の方法、 Unicode についての基礎知識、良いプログラマの雇い方、非技術系マネージャの頭の中など、多岐に渡る話題に対して彼なりの考え方を書いたものだ。
この本について書評を書こうと思ったのは内容が非常に良かったからに他ならない。本の帯には「マネジメントの世界にようこそ!」とあるが、よくあるマネジメントに関する教科書のように(というか、マネジメントに限らず退屈な教科書によく見られることだが)無味乾燥な解説が並んでいるのではない。ユーモア溢れる文体で笑いながら読めるのである。技術書なのに、まるで落語家が喋っているかのように私は感じた。
例えば Unicode に関する章(*)には次のような段落がある。
(*)「すべてのソフトウェア開発者が絶対確実に知っていなければならない Unicode とキャラクタセットに関する最低限のこと(良い訳なし!)」という章題からして面白い。
この本はLinuxのコマンドラインだとか、特定のプログラミング言語だとか、今流行の技術だとかについては解説しない。この本は、あなたがプログラムを作って売る会社で働く、またはそのような会社を経営するとして、どうすればビジネスとして成功するかを解説している。あなたがプログラマなら、古いクズコードを捨ててスクラッチから書き直したいと思ったことがあるだろう。ビジネスをする上で、それがいかに悪い戦略であるかを、プログラマなら誰でも納得できる理由とともに説明している。
私がお気に入りなのは「氷山の秘密、明らかに」という章だ。題名からは何の話だかまったく分からないが、つまりこういうことだ:プログラミング作業全体を氷山として見たとき、ユーザインターフェースに関する部分は水面に出ている10%程度でしかない。だから、UI以外の部分を作るのに全体のスケジュールの90%の時間がかかるのだ。そして「プログラマ以外の人々はこの事実を理解していない。(p.212)」
章題の面白さもさることながら、本文も筆者の体験を踏まえて非常にコミカルに書かれ、それでいて明日からさっそく役立ちそうな実践的な話になっている。顧客または非技術系マネージャがあなたのプログラムを見る時はUIしか見ないので、プロトタイプとして最初にほとんど完璧なUIを見せてしまうと、彼らはその時点でプログラムが完成していると思ってしまう。そして、残りの期間、「人々はあなたが何をしているのか分からず、何もしていないと思うのだ。(p.213)」
この本は次のような人におすすめする。
この本の主軸は、ビジネスとしてソフトウェア開発が成功する方法について、である。その世界では、高品質なソフトウェアをなるべく出荷することが正義であり、プログラマ生活を楽しく過ごすことが正義である。そのためにスケジュール管理や仕様書が大切であり、有能なプログラマを雇って集中できる環境を作ることが大切なのだ。
この本について書評を書こうと思ったのは内容が非常に良かったからに他ならない。本の帯には「マネジメントの世界にようこそ!」とあるが、よくあるマネジメントに関する教科書のように(というか、マネジメントに限らず退屈な教科書によく見られることだが)無味乾燥な解説が並んでいるのではない。ユーモア溢れる文体で笑いながら読めるのである。技術書なのに、まるで落語家が喋っているかのように私は感じた。
例えば Unicode に関する章(*)には次のような段落がある。
私は宣言する。もしあなたが21世紀において仕事しているプログラマであり、キャラクタ、キャラクタセット、エンコーディング、Unicodeの基本について知らないのであれば、私はあなたをひっ捕まえて、潜水艦で6ヶ月間のたまねぎ剥きの刑に処する。絶対そうするから。私はこれを読んだときゲラゲラと笑ってしまった。Unicodeに関する技術的な記事なのに、である。このように楽しい表現が本書の随所に見られ、Joel さんの文章力(人心掌握力)に感心するばっかりだ。私は日本語訳を読んでいるので、訳者の青木靖さんのユーモアセンスによる部分もあるかもしれないけど。
(*)「すべてのソフトウェア開発者が絶対確実に知っていなければならない Unicode とキャラクタセットに関する最低限のこと(良い訳なし!)」という章題からして面白い。
この本はLinuxのコマンドラインだとか、特定のプログラミング言語だとか、今流行の技術だとかについては解説しない。この本は、あなたがプログラムを作って売る会社で働く、またはそのような会社を経営するとして、どうすればビジネスとして成功するかを解説している。あなたがプログラマなら、古いクズコードを捨ててスクラッチから書き直したいと思ったことがあるだろう。ビジネスをする上で、それがいかに悪い戦略であるかを、プログラマなら誰でも納得できる理由とともに説明している。
私がお気に入りなのは「氷山の秘密、明らかに」という章だ。題名からは何の話だかまったく分からないが、つまりこういうことだ:プログラミング作業全体を氷山として見たとき、ユーザインターフェースに関する部分は水面に出ている10%程度でしかない。だから、UI以外の部分を作るのに全体のスケジュールの90%の時間がかかるのだ。そして「プログラマ以外の人々はこの事実を理解していない。(p.212)」
章題の面白さもさることながら、本文も筆者の体験を踏まえて非常にコミカルに書かれ、それでいて明日からさっそく役立ちそうな実践的な話になっている。顧客または非技術系マネージャがあなたのプログラムを見る時はUIしか見ないので、プロトタイプとして最初にほとんど完璧なUIを見せてしまうと、彼らはその時点でプログラムが完成していると思ってしまう。そして、残りの期間、「人々はあなたが何をしているのか分からず、何もしていないと思うのだ。(p.213)」
この本は次のような人におすすめする。
- 趣味ではなく、仕事でプログラムを書く人
- スケジュール管理をしたり、社長に進捗を報告する必要のある人
- 会社を成功させるためにソフトウェアの開発・販売戦略を考える人
仕様書が大切だ、というと、あの堅苦しい、バインダー数冊分もある分厚い仕様書を書くなんて御免だ!と思うかもしれない。その通り。本書でいう良い仕様書とは、可笑しく、学術論文のように堅苦しくなく、箇条書き・挿絵・チャート・表・空白をたくさん使い、画一的なテンプレートには従わないで書かれた、プログラムの機能仕様書である。仕様書はその製品に関わるプログラマ、品質保証の人、マーケティングの人、マネージャなどが読むための文書であり、プログラマでない彼らが読もうと思える文書にしなければならない。本書には明日から実践できる具体的なルールが詰まっている。
ここでは仕様書に関する本書の内容を紹介したが、スケジュール管理の方法、有能なプログラマを雇う方法、彼らを集中できるようにする方法ももちろん書かれている。ソフトウェアを作って売ることに関係がある方・または将来関係を持つだろう方には、強くこの本をおすすめする。ああ、どうして、私がソフトウェア工学を学んでいた大学院生のときにこの本を読まなかったのだろう。
2015年8月30日日曜日
【自作エミュレータで学ぶx86アーキテクチャ】書店に並ぶ様子まとめ
書店での目撃情報などが出てきたので、ここにまとめます。
書泉ブックタワー
8/27 新刊『コンピュータが動く仕組みを徹底理解!自作エミュレータで学ぶx86アーキテクチャ』 マイナビ (978-4-8399-5474-1) 内田公太・上川大介 著 10冊入荷 pic.twitter.com/mPvlguAN9r
— 書泉ブックタワーコンピュータ書売り場 (@shosen_bt_pc) 2015, 8月 27
丸善 日本橋店
日本橋の丸善では棚に立ててもらえてました。ありがとう丸善! pic.twitter.com/esyswgsTLF
— 雲中の蛇使い (@uchan_nos) 2015, 8月 28
ジュンク堂 渋谷店
エミュレータ本発見!渋谷ジュンク堂にて許可を得て撮影 pic.twitter.com/9YgeFjDAcY
— d-kami (@d_kami) 2015, 8月 28
ジュンク堂 池袋本店
ジュンク堂書店 池袋本店 に並んでいるのを確認しました!渋谷店とは違ってCPUの創りかたの隣ですね。 pic.twitter.com/qRNqAcuoVP
— 雲中の蛇使い (@uchan_nos) 2015, 8月 29
有隣堂 ヨドバシAKIBA店
自作エミュレータで学ぶx86アーキテクチャ 、アキヨドの有隣堂さんで無事確保。Amazonさんのキャンセルも通って一件落着。さてさて、帰ってお楽しみタイム。 pic.twitter.com/QkKGfmVXYC
— Nawo[.jp] (@nawolets) 2015, 8月 29
2015年8月22日土曜日
日本語キーボードを US 配列で使いつつ、変換/無変換キーで IME ON/OFF
僕はキーボードのキー配列は US 配列が好きです。なぜなら記号の位置などが JP 配列より綺麗だからです。JP 配列ではなぜか離れ離れになっている「'」と「"」、「;」と「:」が同じキーに割り当てられていたりします。
でも US 配列のキーボードはちょっと嫌いです。なぜなら「変換」「無変換」キーがないからです。そんなキーは普段使わない、という人もいるかもしれませんが、この 2 つのキーはカスタマイズにちょうどいいと思いませんか。US 配列キーボードのスペースバーは長すぎて無駄だと思いませんか。
僕は「変換」を IME のオンに、「無変換」を IME のオフに割り当てて使うのが好みなので、それらのキーがある JP 配列キーボードは必需品です。半角・全角キーは「今、どちらの設定だったか」を覚えておく必要があって、半角モードにしたいのに間違えて全角になってしまってイライラするのですが、IME のオンオフを別のキーにしておくことで、ステートレスな IME 切り替えを実現できます。(Mac の JP キーボードは最初からそうなっていて素敵ですね)
問題は JP 配列キーボード(例えば REALFORCE108UBK)の大部分のキーを US 配列として使いつつも、変換・無変換キーを有効化して IME オンオフに使うにはどうするかということです。Windows で通常の手順(Windows 8 でキーボードが英語配列キーボードとして認識される)でキーボードレイアウトを「101 キーボード」にしてしまうと、変換・無変換キーが存在しない純粋な US 配列キーボードとして扱われてしまって問題を解決できません。
そこで AX 配列(参考:右Altキーに[漢字]キーを割り当てる方法 )を使います。AX 配列とは参考記事に書いてある通り、 US 配列に必要最低限の変更を加えて(つまり記号の位置などを極力変更せず)日本語環境で使いやすくした配列であり、今回の問題にピッタリなのです。
AX 配列への変更は参考記事を参照していただくとして、ここでは AX 配列に変更した後にやるとよいキー配置変更を説明します。AX 配列に変更してみると分かると思いますが、JP 配列キーボードの「}]」キー(Enter の左下)を押すと「\」が入力されてしまったり、「\|」キー(Back Space の左)を押しても何も入力されなかったりと、少し不便です。さらに重要なことに、変換・無変換キーを IME の切り替えに割り当てることができない状態になっています。
ということでレジストリの HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Keyboard Layout に「Scancode Map」というバイナリ値を書き込みます。
 この方法は日本語キーボードを英語キーボードとして使う - Nikepを大いに参考にしています。Scancode Map は実際に押されたキーをどのキーに変換するかを定義するもので、上図の値は具体的に次の設定を表します。
この方法は日本語キーボードを英語キーボードとして使う - Nikepを大いに参考にしています。Scancode Map は実際に押されたキーをどのキーに変換するかを定義するもので、上図の値は具体的に次の設定を表します。
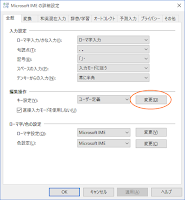 変換と無変換が押されたときの挙動を「IME-オン」「IME-オフ」に対応付けます。
変換と無変換が押されたときの挙動を「IME-オン」「IME-オフ」に対応付けます。

でも US 配列のキーボードはちょっと嫌いです。なぜなら「変換」「無変換」キーがないからです。そんなキーは普段使わない、という人もいるかもしれませんが、この 2 つのキーはカスタマイズにちょうどいいと思いませんか。US 配列キーボードのスペースバーは長すぎて無駄だと思いませんか。
僕は「変換」を IME のオンに、「無変換」を IME のオフに割り当てて使うのが好みなので、それらのキーがある JP 配列キーボードは必需品です。半角・全角キーは「今、どちらの設定だったか」を覚えておく必要があって、半角モードにしたいのに間違えて全角になってしまってイライラするのですが、IME のオンオフを別のキーにしておくことで、ステートレスな IME 切り替えを実現できます。(Mac の JP キーボードは最初からそうなっていて素敵ですね)
問題は JP 配列キーボード(例えば REALFORCE108UBK)の大部分のキーを US 配列として使いつつも、変換・無変換キーを有効化して IME オンオフに使うにはどうするかということです。Windows で通常の手順(Windows 8 でキーボードが英語配列キーボードとして認識される)でキーボードレイアウトを「101 キーボード」にしてしまうと、変換・無変換キーが存在しない純粋な US 配列キーボードとして扱われてしまって問題を解決できません。
そこで AX 配列(参考:右Altキーに[漢字]キーを割り当てる方法 )を使います。AX 配列とは参考記事に書いてある通り、 US 配列に必要最低限の変更を加えて(つまり記号の位置などを極力変更せず)日本語環境で使いやすくした配列であり、今回の問題にピッタリなのです。
AX 配列への変更は参考記事を参照していただくとして、ここでは AX 配列に変更した後にやるとよいキー配置変更を説明します。AX 配列に変更してみると分かると思いますが、JP 配列キーボードの「}]」キー(Enter の左下)を押すと「\」が入力されてしまったり、「\|」キー(Back Space の左)を押しても何も入力されなかったりと、少し不便です。さらに重要なことに、変換・無変換キーを IME の切り替えに割り当てることができない状態になっています。
ということでレジストリの HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Keyboard Layout に「Scancode Map」というバイナリ値を書き込みます。
- 1D,00,3A,00 : 3A (Caps Lock) → 1D (Ctrl)
- 3A,00,1D,00 : 1D (Ctrl) → 3A (Caps Lock)
- 1C,00,2B,00 : 2B (JP }] key) → 1C (Enter)
- 2B,00,7D,00 : 7D (JP |\ key) → 2B (JP }] key)
- 36,00,73,00 : 73 (JP _\ key) → 36 (Right Shift)
- 38,E0,70,00 : 70 (JP kana) → E0 38 (Right Alt)
- 5B,00,79,00 : 79 (JP henkan) -> 5B
- 5A,00,7B,00 : 7B (JP muhenkan) -> 5A
IME のプロパティから「詳細設定」画面を開き、キー設定の「変更」をクリックします。

以上で設定は完了です。快適なキーボードライフをお過ごしください!
2015年8月14日金曜日
出版のお知らせ 『自作エミュレータで学ぶx86アーキテクチャ』
久しぶりのブログ更新となりました。
理由の一つは、ここ数ヶ月は暇さえあれば本の原稿を書いていたからです。
本のタイトルはちょっと長いですが
『自作エミュレータで学ぶx86アーキテクチャ コンピュータが動く仕組みを徹底理解!』
ということになりました。
8月28日に出版予定でございます。
2015年8月23日更新:
Kindle 版が 2,152円+税で予約開始したようです。
自作エミュレータで学ぶx86アーキテクチャ コンピュータが動く仕組みを徹底理解!
共著の方(d-kamiさん)のブログでも紹介されています。
というわけで本を出版します - マイペースなプログラミング日記
タイトルの通り、この本はx86 CPUの機械語を実行するエミュレータソフトウェアを作りながらx86アーキテクチャを学んでいこうという本です。例えば
2015年8月25日更新:
本書で作るエミュレータは x86 の中でも一部の機能を実装したとてもシンプルなものです。一言で表せば、オペランドサイズが 32 ビットのリアルモードエミュレータです。リアルモードの全命令を実装しているわけではありませんし、セグメント機構など高度な機能も実装しませんが、それでも C 言語で書いたプログラムを動かすことができるくらいの機能は持っています。人によっては物足りなく感じる方もいらっしゃると思いますが、本書は C 言語を学び終えたくらいの人が次に読む本を想定していますのでご了承ください。
CPUに閉じることなく、CPUとその周りとの関連も扱っています。x86 CPUはメインメモリにスタック構造を作ります。C言語入門した直後だとそもそもスタックを知らないかもしれませんので、一般的なスタックの話から始めて実際にメモリ上に作られるスタックフレームの話まで書いています。また、メモリより外の世界としてI/Oの話も扱います。CPUはI/Oを介して外界に繋がらなければ役立つ仕事はできません。エミュレータに
最後の章では、実機でプログラムを実行する方法も説明しています。USBメモリのブートセクタに自作の機械語を書き込み、パソコンを起動させ、OSの力を借りずにプログラムを実行させます。BIOSの文字表示機能を使って、色付きの文字列を画面に表示させるのがゴールです。
理由の一つは、ここ数ヶ月は暇さえあれば本の原稿を書いていたからです。
本のタイトルはちょっと長いですが
『自作エミュレータで学ぶx86アーキテクチャ コンピュータが動く仕組みを徹底理解!』
ということになりました。
8月28日に出版予定でございます。
2015年8月23日更新:
Kindle 版が 2,152円+税で予約開始したようです。
自作エミュレータで学ぶx86アーキテクチャ コンピュータが動く仕組みを徹底理解!
共著の方(d-kamiさん)のブログでも紹介されています。
というわけで本を出版します - マイペースなプログラミング日記
タイトルの通り、この本はx86 CPUの機械語を実行するエミュレータソフトウェアを作りながらx86アーキテクチャを学んでいこうという本です。例えば
inc [ebp-4]を機械語に変換するとff 45 fcになり、それぞれがオペコード、ModR/M、ディスプレースメントに対応することを学びます。ModR/Mの中も実はビット単位で意味があり、Mod、REG、R/Mに分かれているんだよという話もします。2015年8月25日更新:
本書で作るエミュレータは x86 の中でも一部の機能を実装したとてもシンプルなものです。一言で表せば、オペランドサイズが 32 ビットのリアルモードエミュレータです。リアルモードの全命令を実装しているわけではありませんし、セグメント機構など高度な機能も実装しませんが、それでも C 言語で書いたプログラムを動かすことができるくらいの機能は持っています。人によっては物足りなく感じる方もいらっしゃると思いますが、本書は C 言語を学び終えたくらいの人が次に読む本を想定していますのでご了承ください。
CPUに閉じることなく、CPUとその周りとの関連も扱っています。x86 CPUはメインメモリにスタック構造を作ります。C言語入門した直後だとそもそもスタックを知らないかもしれませんので、一般的なスタックの話から始めて実際にメモリ上に作られるスタックフレームの話まで書いています。また、メモリより外の世界としてI/Oの話も扱います。CPUはI/Oを介して外界に繋がらなければ役立つ仕事はできません。エミュレータに
in/out命令とキャラクタデバイスを実装し、実際にキーボード入力とディスプレイ出力を行えるようにしてみます。最後の章では、実機でプログラムを実行する方法も説明しています。USBメモリのブートセクタに自作の機械語を書き込み、パソコンを起動させ、OSの力を借りずにプログラムを実行させます。BIOSの文字表示機能を使って、色付きの文字列を画面に表示させるのがゴールです。
1章では、皆さんが知ってるであろうC言語が、実際にCPUで実行されるときにどのような機械語になるか、バイナリを逆アセンブルしたりしながら学びます。16進数とか2の補数もここで学びます。
— 雲中の蛇使い (@uchan_nos) 2015, 8月 11
2章では、C言語の中でもポインタに絞って機械語やアセンブリ言語との関連を見ていきます。通常の変数とポインタ変数は、アセンブリの世界ではほとんど同じなんだということを学びます。関数ポインタが出てくるのもこの章です。
— 雲中の蛇使い (@uchan_nos) 2015, 8月 11
3章が中核となる章で、CPUが命令を実行する過程やModR/M、フラグレジスタの話をします。分岐命令とスタックフレームも説明します。leave命令をエミュレータに実装し終わるとC言語で書いたプログラムを動かせるようになります。
— 雲中の蛇使い (@uchan_nos) 2015, 8月 11
4章では、BIOSやブートセクタの説明をして、実機起動に向けて知識を付けます。最後に本物のUSBメモリにブートセクタを書き込んで起動してみます。
— 雲中の蛇使い (@uchan_nos) 2015, 8月 11
この本はC言語の入門書を読み終わったくらいのレベルの人が読めることを目指して書いているため、C言語プログラミングで入門の次に知ると良さそうな事柄、例えばファイル分割の方法とか、printfで色付きの文字列を出力する方法なども扱っています。1章分のページをまるまる使って、アセンブリ言語の視点からポインタを学び直すので、C言語のポインタで躓いてしまった人にも何らかのひらめきを与えられる可能性があります。
また、本書を通してx86エミュレータというある程度の規模のソフトウェアを作りあげる経験を通して、読者のプログラミング能力を養おうという裏の目標もあったりします。手軽にx86の機械語を実行できる環境を作るという(ある意味)実用的なゴールを持ってプログラミングを行うことで、学習のための学習より効果の高いプログラミング練習になるでしょう。
お近くの書店で目についた際にチラ見していただければ幸いです。
最後に目次情報を載せておきます。
最後に目次情報を載せておきます。
Chapter 1: C言語とアセンブリ言語
- 1.1. C言語から機械語へ
- 1.2. 機械語とアセンブリ言語
- 1.3. 機械語に飛び込む
- 1.4. アセンブリ言語を少し詳しく
- 1.5. 基本のmov命令
- 1.6. インクリメント専用のinc命令
- 1.7. 16進数入門
- 1.8. 2の補数入門
Chapter 2: ポインタとアセンブリ言語
- 2.1. レジスタ
- 2.2. メモリ
- 2.3. 初めてのエミュレータ
- 2.4. ポインタの復習
- 2.5. ポインタに飛び込む
- 2.6. 構造体とポインタ
- 2.7. 不完全型とポインタ
- 2.8. 関数ポインタ
Chapter 3: CPUがプログラムを実行する仕組み
- 3.1. プログラムの配置
- 3.2. エミュレータのorg対応
- 3.3. プログラムの実行
- 3.4. エミュレータのModR/M対応
- 3.5. 無条件分岐命令
- 3.6. call命令とスタック
- 3.7. エミュレータのcall対応
- 3.8. ローカル変数とスタック
- 3.9. フラグレジスタと条件分岐命令
- 3.10. エミュレータの条件分岐命令対応
- 3.11. プログラムの繰り返し
- 3.12. デバイスアクセス
Chapter 4: BIOSの仕組みと実機起動
- 4.1. BIOS
- 4.2. BIOSの実装
- 4.3. 割り込み
- 4.4. ブートセクタ
- 4.5. PBRを見てみよう
- 4.6. 実機で動かしてみよう
2015年7月17日金曜日
Lavie Direct HZ に Arch Linux をインストール
大まかな流れは Installation guide - ArchWiki に沿えばいいのですが、幾つかハマりポイントがあったのでメモを残しておきます。
起動メディアの準備
Lavie Direct HZ(以下 Lavie)には DVD ドライブなどは無いので USB 経由の何かで起動することになります。今回は USB メモリでやることにしました。
USB メモリへの書き込みは Silicon Linux さんの DD for Windows とか John Newbigin さんの dd for windows などを利用すれば簡単です。これらのツールは管理者権限で起動するのがポイントといえばポイントでしょうか。
インストーラの起動
工場出荷時の設定にも依るのでしょうが、僕が買ったマシンでは UEFI が USB 系のメディアより内蔵 SSD を優先して起動する設定になっていたので、 Lavie 起動画面で F2 を押して UEFI の設定画面に行き、起動優先度を変更しておきます。
さらに(少なくとも僕のマシンでは) UEFI のセキュアブートが有効になっているので、先ほど準備した USB メモリを挿して電源を入れても「Failed to Start loader」というエラーが出てインストーラが起動しません。セキュアブートを無効にしておきましょう。
※ Unified Extensible Firmware Interface - ArchWiki では loader.efi と vmlinuz.efi に対して Enroll Hash (ハッシュ値を登録)を実行して回避する手順が載ってますが、後々で別のエラー(Secure Boot Violation)が出ますので、セキュアブートを無効にしてしまうのが手っ取り早いでしょう。
さらに(少なくとも僕のマシンでは) UEFI のセキュアブートが有効になっているので、先ほど準備した USB メモリを挿して電源を入れても「Failed to Start loader」というエラーが出てインストーラが起動しません。セキュアブートを無効にしておきましょう。
※ Unified Extensible Firmware Interface - ArchWiki では loader.efi と vmlinuz.efi に対して Enroll Hash (ハッシュ値を登録)を実行して回避する手順が載ってますが、後々で別のエラー(Secure Boot Violation)が出ますので、セキュアブートを無効にしてしまうのが手っ取り早いでしょう。
フォントの調整
インストーラが起動して最初に思うのは、きっと「フォントちっさ!」だと思います^^;
Lavie は解像度が高すぎ、普通のフォントだと小さすぎるわけです。目が疲れてしまいますので、大きいフォントをインストールしましょう。My fonts are too tiny で紹介されている Terminus font を入れることにします。
まず、ワイヤレスネットワークの設定を済ませます。Installation guide の "Connect to the Internet" を参考に wifi-menu コマンドを使えば簡単に設定できます。
インターネットアクセスができるようになったら pacman のミラーリストで日本のミラーを一番上に持っていきます(ミラーの設定は必須ではないですが pacman の動作速度に大きな影響があります)。その後 pacman -Syy でパッケージリストを更新します。更新が完了したら pacman -S terminus-font でフォントをインストールしましょう。 /usr/share/kbd/consolefonts/ 以下に ter-xxx.psf.gz みたいなフォントファイルがインストールされるはずです。
最後にフォントを適用します。 setfont ter-128n (28 がサイズを表します。Terminus font の最高は 32 のようです。)でちょうどいい大きさのフォントになるはずです。128b とか 228n/b とか u28n/b みたいなフォントファイルもあるようですが、違いは分かりませんでした。
efibootmgr コマンドを使うとあたかも優先度を変更できそうなのですが、 Lavie の UEFI 実装と相性が悪いのか、再起動すると優先度設定が元に戻ってしまうようです。
また、何度も再起動を繰り返す中で、タッチパッドが使えない時は必ず起動後の 1 文字目のキーボード入力が捨てられることも判明していました。ログイン画面でユーザ名を入力する際、 1 文字目が入力できないのです。したがって、キーボードコントローラ周りの初期化にミスってるのではないかと見当を付けて解決法を探しました。
解決に導いてくれたのは Touchpad not recognized on new Ultrabook という質問でした。この中の回答で i8042.nomux オプションを付けたら解決するかも、という記述があり試しました。結果としてこのオプションは僕の環境では効果はありませんでした。しかし i8042.nomux をキーワードに検索してみると What does the 'i8042.nomux=1' kernel option do during booting of Ubuntu? という質問に辿り着き、 i8042.reset の存在が分かりました。
数回再起動実験をしていますが、今のところすっかり直っている感じです。
ブートローダの優先度設定
UEFI ブートをしたかったので GRUB を選びました。普通に GRUB をインストールし grub-mkconfig した後再起動しても Windows のブートローダが立ち上がってしまうので、 UEFI の設定画面(起動時に F2 を押すやつ)の Boot タブの "Hard Disk Drive BBS Priorities" から優先度を変えてやります。1st Boot として arch_grub を指定してあげれば OK です。efibootmgr コマンドを使うとあたかも優先度を変更できそうなのですが、 Lavie の UEFI 実装と相性が悪いのか、再起動すると優先度設定が元に戻ってしまうようです。
タッチパッドが(時々)効かない
僕の場合はカーネルの起動オプションに i8042.reset を付け加えることで解決できました。/etc/default/grub の GRUB_CMDLINE_LINUX_DEFAULT に i8042.reset を加え、 sudo grub-mkconfig -o /boot/grub/grub.cfg とします。以下、解決するまでのストーリー
タッチパッドが効くときと効かないときの xinput コマンドの出力を比べてみると、デバイスが検出できているかどうかの問題切り分けができます。僕の場合、この時点でデバイスが検出できてないことが分かっていました。また、何度も再起動を繰り返す中で、タッチパッドが使えない時は必ず起動後の 1 文字目のキーボード入力が捨てられることも判明していました。ログイン画面でユーザ名を入力する際、 1 文字目が入力できないのです。したがって、キーボードコントローラ周りの初期化にミスってるのではないかと見当を付けて解決法を探しました。
解決に導いてくれたのは Touchpad not recognized on new Ultrabook という質問でした。この中の回答で i8042.nomux オプションを付けたら解決するかも、という記述があり試しました。結果としてこのオプションは僕の環境では効果はありませんでした。しかし i8042.nomux をキーワードに検索してみると What does the 'i8042.nomux=1' kernel option do during booting of Ubuntu? という質問に辿り着き、 i8042.reset の存在が分かりました。
数回再起動実験をしていますが、今のところすっかり直っている感じです。
2015年6月16日火曜日
Linux Network Namespace メモ
勉強資料
Introducing Linux Network Namespacesチュートリアル形式で基礎が学べる
Linux Switching – Interconnecting Namespaces
veth ペアの基礎や Linux Bridge/Open vSwitch での 2 つの名前空間の接続が図入りで解説されている
Linux Network Namespace で遊んでみる
具体的なコマンド例が多数
network lxc Linux Containers
LXC とネットワーク名前空間を関連させた話
「ネットワーク名前空間は1つ以上のプロセスに割り当てられたプライベートなネットワークリソースの集合」
ifconfig vs ip
ifconfig は deprecated になりこれからは ip の時代。ということで具体例でコマンドの比較。
LXC と ネットワーク名前空間
veth ペアの片側を LXC コンテナの名前空間に移動させる
# lxc-info -n NAMEでそのコンテナの init の PID が分かる。その PID に対して
# ip link set VETHNAME netns PIDとやれば veth ペアの片側(VETHNAME で指定した側)が PID が属する名前空間に移動する。
移動後に確認するには下記コマンドを実行してみる。
# lxc-console -n NAMEでコンテナに入り込んでから
[root@arch1 ~]# ip link 1: lo:みたいに VETHNAME がちゃんとコンテナに移動したことが分かる。(この例では VETHNAME = veth-arch)mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 6: veth-arch: mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000 link/ether 3e:a5:f7:ed:54:9a brd ff:ff:ff:ff:ff:ff link-netnsid 0
veth ペアの片側を元の名前空間に引き戻す
普通、ある名前空間から別の名前空間にネットワークインタフェースを移動するには# ip netns exec 移動元名前空間 ip link set インターフェース名 netns 移動先名前空間としてやればよい。が、移動元名前空間が ip netns add 以外で作ったもの(LXC の名前空間はまさにそれ)である場合、名前空間に名前が付いてなくてコマンドが実行できない。
ということで、まずは一時的な名前空間名を付与してあげる。
# ln -s /proc/PID/ns/net /var/run/netns/NSNAMEPID はコンテナの PID で NSNAME は任意の名前空間名。/proc/PID/ns/net が「PID が属する名前空間」を表すファイルになっている。
とにかく /var/run/netns/ 以下に名前を付けてあげると ip コマンドが認識するという仕組み。(ここでは NSNAME = ns-arch1)
# ls /var/run/netns ns-arch1 # ip netns list ns-arch1 (id: 0)
こんな感じに名前が付けば、あとは ip netns exec コマンドを使うだけ。
# ip netns exec NSNAME ip link set VETHNAME netns NSNAME_TO
NSNAME_TO にはもちろん PID も指定できて、つまり 1 を指定してあげると元々の名前空間に VETHNAME が戻ってくる。親元に帰ってくる子どもみたいな感じ。
個人的には ip netns exec NSNAME にも PID を指定させてくれればいいのに、と思うけどなぜかそれは出来ないので、リンクを張るという技を使わざるを得ないようだ。
作ったリンクは iproute2 も LXC も管理してないものなので、必要が無くなったら手動で削除しておくのが望ましい。
# rm /var/run/netns/NSNAME
以上の知識はツイッターで教えていただいた。ありがとうございます。
https://twitter.com/Flast_RO/status/610953725054615552
2015年5月31日日曜日
Qt Creator で Qt Quick アプリを作るときの落とし穴回避 & TIPS
接続した Android タブレットが「互換性のないデバイス」と表示されてしまう
その Android が armeabi-v7a アーキテクチャのときに Android for x86 などのキットを使うと互換性がない。プロジェクトのプロパティ画面で、対象のアーキテクチャ用のキットを追加する。
目的のアーキテクチャ用のキットが見当たらない場合は maintenancetool.exe で追加インストールする。
maintenancetool.exe はスタートメニューの Qt の中にショートカットがあるはず。Qt のインストールディレクトリから直接起動してもよい。
QML ファイルを追加したけど、変更しても反映されないことがある
QML ファイルが Makefile の依存関係に取り込まれていない可能性があるので「ビルド」 >「qmake の実行」で Makefile を更新してみる。2015年4月5日日曜日
読みやすいソースコードを書く方法
読みやすいソースを書くために気をつけていることを軽くまとめてみます。ソースコード例は Python ですが、特に言語に関係なく通用する話題です。業務などでコーディングする際の参考になれば幸いです。
ただ、闇雲にコメントを書けばよいかというとそうでもありません。多くの入門書にも書いてあることですが、コメントにも悪いコメントと良いコメントがあります。一般に、ソースコードから一瞬で分かることをコメントで書いてはいけません。関数コメントの例で言えば、get_size() に対して「サイズを返す」とコメントするのは単なるタイプ数の無駄というものです。関数名だけで十分な情報は伝わっていますから。一方で get_host() に対し「Host クラスのインスタンスを返す」とコメントするのは価値があります。この関数がホスト名でなく Host クラスのインスタンスを返すことが分かるからです。
一見して分かる情報はコメントしないという一般原則を頭に置きつつ、以下ではコメントのパワーが最大に発揮できる場面を考えていきましょう。
関数コメントには最低限、その関数が何をするかという一言を書いて下さい。簡単な関数ならそれだけで十分です。少し大きな関数には、引数と戻り値の意味をコメントします。実践に則した関数の使用例があるとなお良いです。Python なら関数コメントに実行例を含めて python -m doctest hoge.py などと自動テストができますから、そのテストに合格するように書くと完璧です。
良い名前を付ける
最優先で気をつけるのはこれです。「プログラミングは『名前』が9割」と言われることもあるくらい、名前付けには時間を割くべきだと思います。良い名前を付ければプログラムの見通しが良くなり全体像を把握しやすくなりますし、他人(または未来の自分)が保守しやすいソースコードになります。
では良い名前とはなんでしょうか?自分なりにまとめてみました。
名前と内容を一致させる
関数名なら処理内容を端的に表す名前にすべきですし、逆に名前から想像できない処理はしてはいけません。
私は実際に、副作用を持った operator +() の実装を見たことがあります。内部でメンバ変数を書き換えていたのです。 operator +() は C++ の機能で、自作クラスに関する加算(a + b)を独自に定義できるのですが、加算演算子ですからもちろん(外から見える)副作用を持つべきではありません。これは、関数が名前から想像できない処理をしてしまっている例です。
動的型付け言語ではもっと注意が必要なことがあります。例えば get_host() という関数を見たとき、これが Host クラスのインスタンスを返すのか、ホスト名を文字列として返すのか、新人さんは迷うはずです。ただ get_host() 自体は適切な関数名ですから、これを変えるのは難しいです。それより、ホスト名を扱う変数は常に host_name という名前にする、 get_host() の戻り値を host_obj という変数で受け取るなど、ホスト名と Host インスタンスを区別するように意識しましょう。
動的型付け言語ではもっと注意が必要なことがあります。例えば get_host() という関数を見たとき、これが Host クラスのインスタンスを返すのか、ホスト名を文字列として返すのか、新人さんは迷うはずです。ただ get_host() 自体は適切な関数名ですから、これを変えるのは難しいです。それより、ホスト名を扱う変数は常に host_name という名前にする、 get_host() の戻り値を host_obj という変数で受け取るなど、ホスト名と Host インスタンスを区別するように意識しましょう。
boolを返す関数はcheck…にしない
例えば hoge.check_available() だと hoge が有効なのが戻り値が真のときか偽のときか分かりません。 hoge.is_available() であれば紛れはありません。if 文の条件に書いたときに英文として自然になる名前を選ぶようにすると良いでしょう。
is, has など英語の三人称単数形を使うと適切なことが多いですが、敢えて動詞を使わないこともあります。例えば C++ のコンテナには、要素が空かどうかを調べる関数 empty() があります。これは形容詞だけの名前ですが、下手に check_empty() とするより分かりやすい関数名ですね。
is, has など英語の三人称単数形を使うと適切なことが多いですが、敢えて動詞を使わないこともあります。例えば C++ のコンテナには、要素が空かどうかを調べる関数 empty() があります。これは形容詞だけの名前ですが、下手に check_empty() とするより分かりやすい関数名ですね。
コメントを付ける
これも基本中の基本でしょう。コメントはソースコードの理解を大幅に助けてくれますし、自分が後で読み返すときも、ソースコード断片を一つのかたまりとして思い出すのに大いに役立ちます。ただ、闇雲にコメントを書けばよいかというとそうでもありません。多くの入門書にも書いてあることですが、コメントにも悪いコメントと良いコメントがあります。一般に、ソースコードから一瞬で分かることをコメントで書いてはいけません。関数コメントの例で言えば、get_size() に対して「サイズを返す」とコメントするのは単なるタイプ数の無駄というものです。関数名だけで十分な情報は伝わっていますから。一方で get_host() に対し「Host クラスのインスタンスを返す」とコメントするのは価値があります。この関数がホスト名でなく Host クラスのインスタンスを返すことが分かるからです。
一見して分かる情報はコメントしないという一般原則を頭に置きつつ、以下ではコメントのパワーが最大に発揮できる場面を考えていきましょう。
関数コメント
関数コメントは本当に役立ちますので、是非書いて下さい。関数コメントは普通、その関数の利用者に向けて書くものですが、関数の実装者にとってもその関数をより良いものにするために役立ちます。容易くコメントが書ける関数は、利用者にとっても直感的に使える関数になりやすく、長く複雑なコメントを書かねばならない関数は、利用も困難な関数になりがちです。関数の利用しやすさを図る尺度として、関数コメントが役立つのです。関数コメントには最低限、その関数が何をするかという一言を書いて下さい。簡単な関数ならそれだけで十分です。少し大きな関数には、引数と戻り値の意味をコメントします。実践に則した関数の使用例があるとなお良いです。Python なら関数コメントに実行例を含めて python -m doctest hoge.py などと自動テストができますから、そのテストに合格するように書くと完璧です。
def fetch_hosts(conn, klass):
'''class が `klass` であるホストオブジェクトすべてをテーブルから読み込んで返す。
conn - DB コネクションオブジェクト
klass - Host クラスのサブクラスオブジェクト
>>> conn = MySQLdb.connect(host='127.0.0.1', db='hostdb')
>>> hosts = fetch_hosts(conn, AppHost)
>>> conn.close()
'''
# do something
ソースコードコメント
ソースコード断片に対してコメントを書くことも可読性の向上に役立ちます。ソースコードを意味のまとまりごとに空行を入れて分け、それぞれのソースコード断片に対して1行から数行のコメントを書くと調度良い感じです。コメントは、その断片が何をしようとしているのか、意図を書くようにします。例えば、注文履歴をもとに各商品が何個売れたかを計算するプログラムにコメントを書いてみます。# 昨日の注文履歴をすべて取得する。
begin_dt = date.today() - timedelta(days=1)
end_dt = date.today()
sells = fetch_sells(conn, begin_dt, end_dt)
# 商品ごとの注文数をカウントする。 { 商品名 : 注文数 }
item_sells = defaultdict(int)
for sell in sells:
item_sells[sell.item_name] += sell.count
このように、それぞれのソースコード断片が何を目的としているかを簡単に書いておくと、他人がソースコードを理解するときにも、自分が後で処理の全体像を読み返すときにも役立ちます。プログラムを単に日本語に変換しただけのような、ソースコードを読めば分かるコメントにならないように注意してください。
setup_db() は UserDB.instance() を初期化してデータベースに接続する関数です。User.instance() はシングルトンの実装になっていますので setup_db() はあるプロセスの中で1回だけ呼び出せば良く、他の場所でユーザ一覧が欲しいと思えば以下のように書くことになります。
ここで、プログラマは setup_db() を呼び出すべきかどうかを考えます。もし、この部分より前で setup_db() が呼び出されるなら、基本的にはここで呼ぶ必要はありません。しかし、もしこの2行が直前の setup_db() の呼び出しと別プロセスで動くなら、再度 setup_db() を呼ぶ必要があります。別プロセスで動くかどうかはこの2行からは判断できず、プログラム全体のアーキテクチャを理解する必要があります。この例では、グローバル変数の使用が保守性を著しく低下させています。
グローバル変数を使わない
グローバル変数やシングルトンなど、どこからでも参照できる変数があるとソースコードが読みにくく、保守しにくくなる場合が多いです。あるソースコード断片が上手く動くかどうかがその変数の状態に依存する場合、分かりにくいバグの原因となります。例えば、DBに接続してユーザ一覧を取得するプログラムを考えます。setup_db() user_db = UserDB.instance() users = user_db.get_users()
setup_db() は UserDB.instance() を初期化してデータベースに接続する関数です。User.instance() はシングルトンの実装になっていますので setup_db() はあるプロセスの中で1回だけ呼び出せば良く、他の場所でユーザ一覧が欲しいと思えば以下のように書くことになります。
# setup_db() ? user_db = UserDB.instance() users = user_db.get_users()
ここで、プログラマは setup_db() を呼び出すべきかどうかを考えます。もし、この部分より前で setup_db() が呼び出されるなら、基本的にはここで呼ぶ必要はありません。しかし、もしこの2行が直前の setup_db() の呼び出しと別プロセスで動くなら、再度 setup_db() を呼ぶ必要があります。別プロセスで動くかどうかはこの2行からは判断できず、プログラム全体のアーキテクチャを理解する必要があります。この例では、グローバル変数の使用が保守性を著しく低下させています。
2015年1月31日土曜日
bossac で Arduino Due に書き込む
Mac OS X Mavericks のターミナルで Arduino Due にプログラムを書き込む方法です。
getting-started_flash.bin をフラッシュメモリに書き込んでみます。
bossac で Arduino Due に書き込む前に stty コマンドで通信速度を 1200 bps に設定するのがミソです。これをやらないと "No device found on cu.usbmodem1411" というエラーが出てしまいます。
まず Arduino IDE 付属の GCC コマンドへのパスを通します。
パスを通したら展開したソースコードの sam/applications/getting-started/sam3x8e_arduino_due_x/gcc に移動します。
最後に make を実行すると、カレントディレクトリに getting-started_flash.bin が出力されるはずです。
ASF には Arduino Due で使えるサンプルプログラムが幾つか入っています。以下のように探せます。
getting-started_flash.bin をフラッシュメモリに書き込んでみます。
stty -f /dev/cu.usbmodem1411 1200 /Applications/Arduino.app/Contents/Java/hardware/tools/bossac -U false -p cu.usbmodem1411 -e -w -v -b getting-started_flash.bin -R
bossac で Arduino Due に書き込む前に stty コマンドで通信速度を 1200 bps に設定するのがミソです。これをやらないと "No device found on cu.usbmodem1411" というエラーが出てしまいます。
サンプルプログラムの準備
ちなみに、書き込むための bin ファイルは ASF (Atmel Software Framework) に付属のサンプルプログラムを GCC でビルドしました。ダウンロードページに "ASF standalone archive for GCC (makefile-based) ..." というリンクがありますので、そこからダウンロードして展開します(執筆時点での最新版が 3.20.1 でした。以下 ~/Downloads/xdk-asf-3.20.1 に展開したとします)。$ export PATH=$PATH:/Applications/Arduino.app/Contents/Java/hardware/tools/gcc-arm-none-eabi-4.8.3-2014q1/bin/ $ cd ~/Downloads/xdk-asf-3.20.1/sam/applications/getting-started/sam3x8e_arduino_due_x/gcc $ make /Applications/Xcode.app/Contents/Developer/usr/bin/make all PROJECT_TYPE=flash CC common/services/clock/sam3x/sysclk.o MKDIR common/services/serial/ CC common/services/serial/usart_serial.o MKDIR common/utils/interrupt/ ... $ ls *.bin getting-started_flash.bin getting-started_sram.bin
パスを通したら展開したソースコードの sam/applications/getting-started/sam3x8e_arduino_due_x/gcc に移動します。
最後に make を実行すると、カレントディレクトリに getting-started_flash.bin が出力されるはずです。
ASF には Arduino Due で使えるサンプルプログラムが幾つか入っています。以下のように探せます。
$ cd ~/Downloads/xdk-asf-3.20.1/sam $ find . -name Makefile | grep arduino ./applications/getting-started/sam3x8e_arduino_due_x/gcc/Makefile ./drivers/adc/adc_example/sam3x8e_arduino_due_x/gcc/Makefile ./drivers/adc/adc_temp_sensor_example/sam3x8e_arduino_due_x/gcc/Makefile ./drivers/adc/adc_threshold_wakeup_example/sam3x8e_arduino_due_x/gcc/Makefile ./drivers/chipid/chipid_example/sam3x8e_arduino_due_x/gcc/Makefile ./drivers/dacc/sinewave_example/sam3x8e_arduino_due_x/gcc/Makefile ./drivers/gpbr/unit_tests/sam3x8e_arduino_due_x/gcc/Makefile ...
2015年1月19日月曜日
同じval++;でもaddになったりincになったり。
最近GCCのビルドをたくさんやってるなかで気づきました。
int val = 0;
val++;
という単純なC言語プログラムでさえ、i386向けのGCCとi686向けのGCCで出力されるバイナリが違うことを。
違うのは変数のインクリメントでした。i386向けGCCは
inc dword [ebp-4]
を出力しました。一方でi686向けGCCは
add dword [ebp-4], 1
を出力したのです。
addの方がバイナリが大きくなるのですが、なぜi686向けはそちらを選択したのか。僕はその理由を知りません。不思議です。
2015/01/20追記
Twitterで良い記事を紹介していただきました。
この記事によれば、inc/dec命令でストールが発生するアーキテクチャがあるそうな。そこで、そういうアーキテクチャではincの代わりにaddを使うんだそうです。
x86アーキテクチャの闇は深い。
2015年1月16日金曜日
Python の exit(), sys.exit(), os._exit() の違い
Python には 3つの似たようなプログラム終了用の関数があります。
exit(), sys.exit(), os._exit()です。
これらの違いを簡単に調べてまとめてみました。
exit 自体が表示されると画面に "Use quit() or Ctrl-D (i.e. EOF) to exit" のようなメッセージを表示し、
exit() と呼び出すと、終了コードを伴って SystemExit 例外を投げる不思議なオブジェクト。
sys.exit() にも言えるが、例外を投げるだけなので、その外側で例外を捕捉してシステムを終了させないようにすることも可能。
つまり、上で紹介した exit() と呼び出し時の挙動は同じ。
これは exit(), sys.exit() と違って、例外を投げるのではなくプロセスを終了させる。
os._exit() は fork() された後の子プロセスを終了させるときに使うのが標準的。
exit(), sys.exit(), os._exit()です。
これらの違いを簡単に調べてまとめてみました。
ものぐさな人へ
- インタラクティブシェルを終了するには exit()
- スクリプトの中でメインプロセスを終了するには sys.exit()
- fork() した子プロセスを終了するには os._exit()
exit([code=None])
site モジュールにより、プログラムの起動時に自動的に追加される定数。exit 自体が表示されると画面に "Use quit() or Ctrl-D (i.e. EOF) to exit" のようなメッセージを表示し、
exit() と呼び出すと、終了コードを伴って SystemExit 例外を投げる不思議なオブジェクト。
sys.exit() にも言えるが、例外を投げるだけなので、その外側で例外を捕捉してシステムを終了させないようにすることも可能。
sys.exit([arg])
終了コードを伴って SystemExit 例外を投げる関数。つまり、上で紹介した exit() と呼び出し時の挙動は同じ。
os._exit(n)
終了ステータス n でプロセスを終了する。これは exit(), sys.exit() と違って、例外を投げるのではなくプロセスを終了させる。
os._exit() は fork() された後の子プロセスを終了させるときに使うのが標準的。
登録:
投稿 (Atom)